

SimpliFeed - News Uncluttered
Your focused news feed, free from distractions and ads


SimpliFeed: Appwrite Hashnode Hackathon
Visit today at simplifeed.org!
Developed by Liam Masters
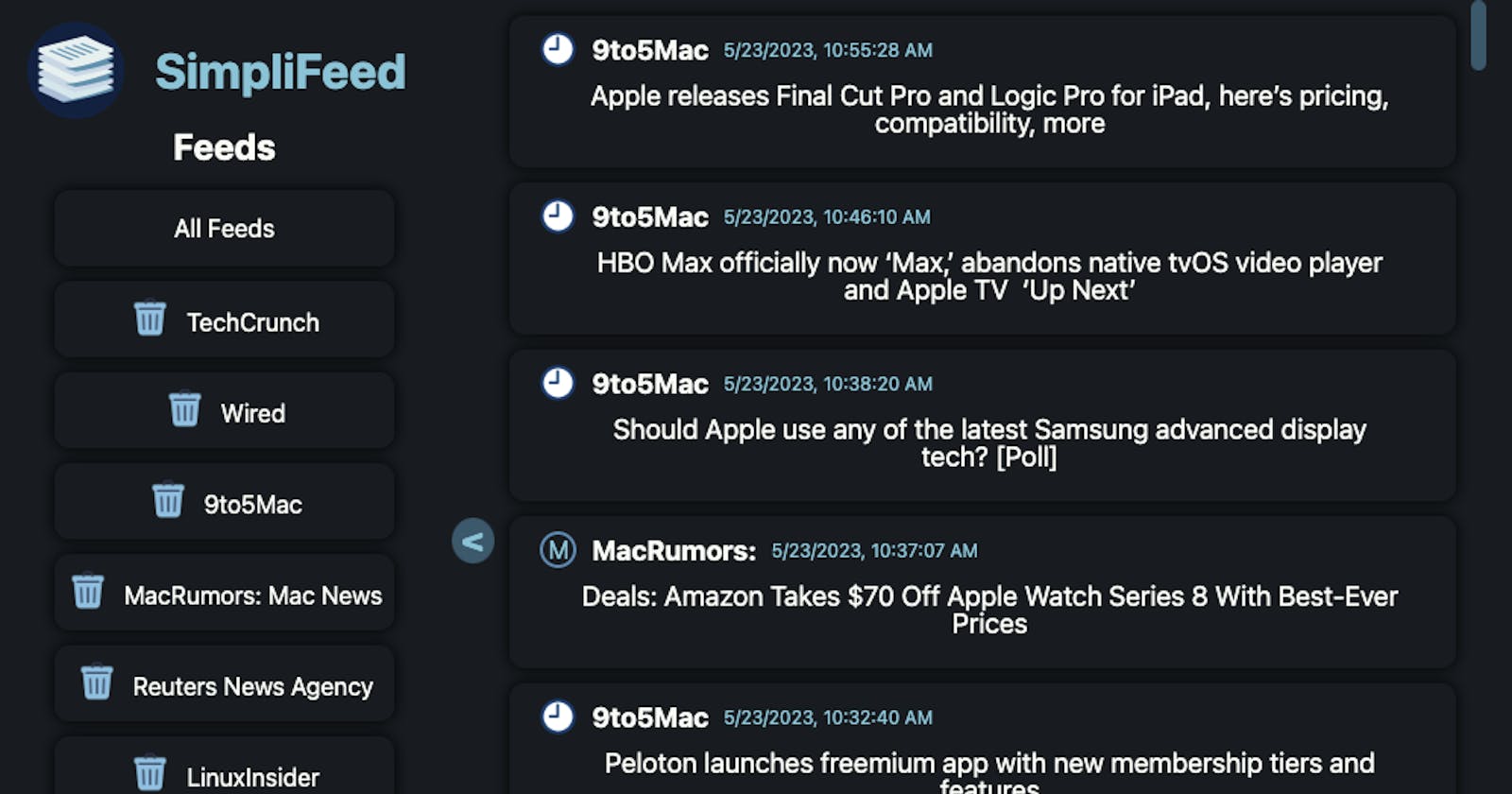
Description of Project
Too much of the news that we get served is dictated by trends and algorithms. SimpliFeed allows you to choose the feeds you want by taking RSS feeds and parsing the articles for the news that you care about. Enter the URL to the feed you want, and SimpliFeed will download the source and distill the content into an easily readable form. Simple.
Tech Stack
Built using Next.js
Auth and Database provided by Appwrite Cloud
Styled with Vanilla CSS
Article parsing server using Python
NGINX reverse proxy, python server, and frontend hosted on AWS
Challenges We Faced
RSS Feed Parsing
RSS feeds come in many shapes and sizes. From the way that the XML is served, to the names and population of various fields, it's a wild west in terms of standardization. I took the approach of exploring many different news and blog sites to see what trends emerged and catered the parsing algorithm to the most common values. The hosting of these files is also very inconsistent, with some only filling in values after the file is loaded using scripts. This poses an issue when just trying to access the source.
Moving forward, I'd like to move the logic for parsing the feeds into the backend. This would allow for the handling of sites filling in fields after the initial request is made, as well as providing more flexibility for parsing feeds in different formats using various RSS+XML models.
UPDATE: All parsing logic has now moved to a python server running in the backend!
News Article Parsing
Once the feed is parsed, we need to enumerate the articles and extract the actual content from the article. Some feeds fill in content directly in the XML data however, the vast majority simply link to the original article. This is not desirable because we don't want to push the user to the news site where they'll be subjected to all of the links and advertising that we're trying to avoid.
The solution I settled on was to extract the text data from the <p> tags on the site and reformat it in my reader section. This does a surprisingly good job of extracting all of the content we care about, without pulling in unnecessary information.
Public Code Repo
Help support the SimpliFeed servers ❤️ https://ko-fi.com/simplifeed
#HashNode
#AppwriteHackathon